Robust DPO#
$ cat projects/robust-dpo.md
Robust DPO
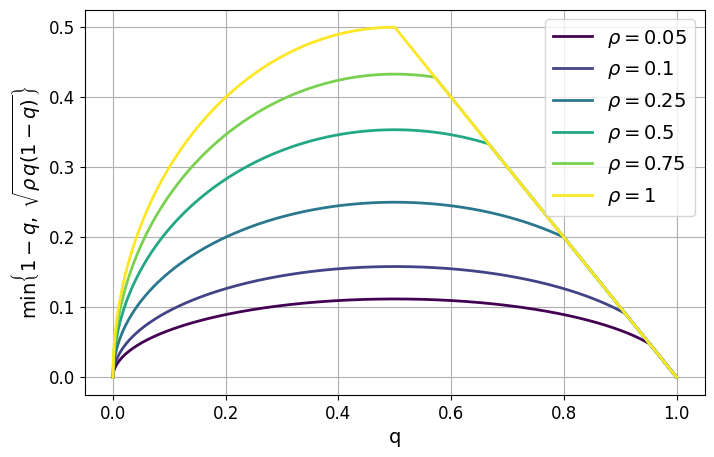
DPO is elegant — it turns RLHF into a supervised learning problem. But it has a dirty secret: it trusts every preference label equally. In practice, human annotators disagree constantly. Feed DPO noisy preferences and it overfits to the noise.
This project adds a distributionally robust layer on top of DPO. The math works out to something intuitive: down-weight preference pairs where the signal is weak. The penalty is highest exactly where annotator uncertainty peaks — near the 50/50 coin-flip zone.
The implementation adds essentially zero overhead. A few extra lines in the loss function, no architectural changes, no extra hyperparameter sweeps. It just makes alignment training more honest about what it doesn’t know.
If you’re doing post-training alignment on LLMs with real human feedback (which is always messy), this is the kind of robustness fix that should probably be on by default.
$ cat /etc/motd
// …built with Claude Code. based on data, but verify.
$ cd ~