Guided Transfer for Diffusion LLMs#
$ cat projects/diffusion-transfer.md
Guided Transfer for Diffusion LLMs
Discrete diffusion models are a different way to do language generation — instead of autoregressive left-to-right, they denoise all tokens in parallel. Cool in theory. In practice, you pretrain one on a big corpus and then need it to work on your specific domain. Fine-tuning is expensive and you probably don’t have enough domain data.
This project solves the transfer problem without touching the pretrained denoiser. The trick is classifier-guided sampling: train a lightweight guide network on your small target dataset and steer the diffusion process at inference time. The hard part was making this efficient — naive ratio-based guidance is exponential in vocab size. A scheduling trick brings it down to linear.
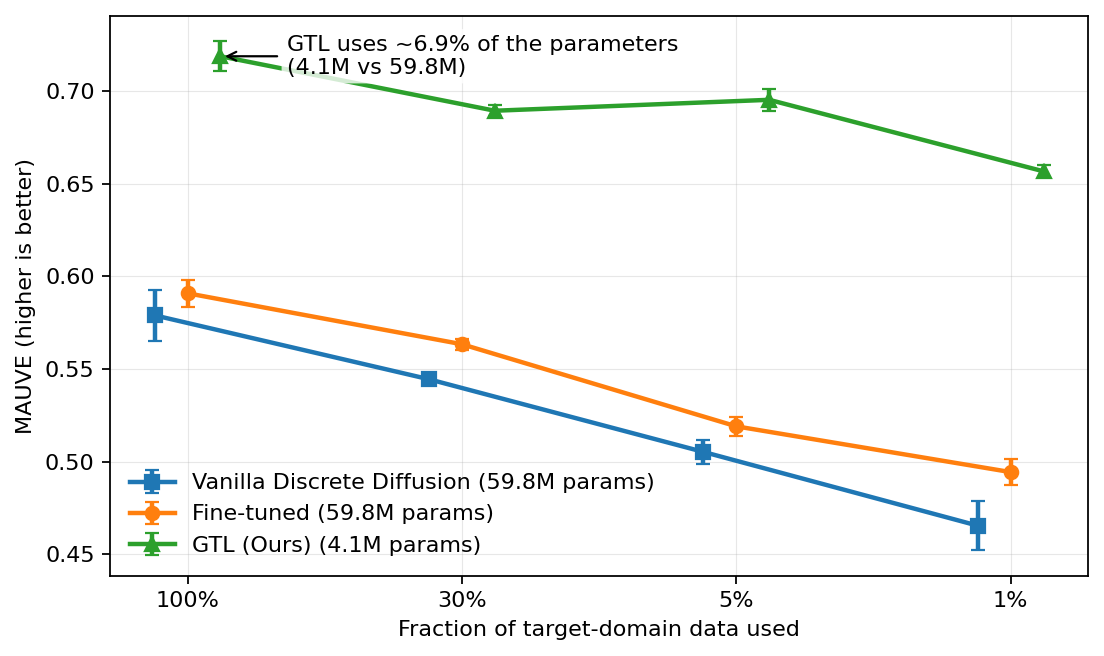
The result: 7% of parameters trained, works across data regimes, and dominates fine-tuning when target data is scarce. That’s the regime that matters in practice — you rarely have millions of domain-specific examples.
$ cat /etc/motd
// …built with Claude Code. based on data, but verify.
$ cd ~